
Programming at its foundation is a set of repeatable ideas that appear across many languages. These ideas include how a program stores values, how it decides what to do next, how it repeats work, and how it groups operations into named units. Describing these shared elements helps learners transfer knowledge from one language to another, because the same underlying concepts are implemented with different syntax and libraries rather than entirely distinct paradigms.
Core elements commonly addressed when learning to write code include representation of information, operations on that information, and the structures that control execution. Understanding these elements in abstract terms — for example, what a variable represents or how a function encapsulates work — can make it easier to read documentation, debug behavior, and compare language choices without relying on language-specific idioms.
Variables and data representation are central to most languages. A variable is a named reference to a value or storage location; implementations differ, with some languages associating a type with the variable itself and others associating type with the value. Primitive types like integers and booleans are usually handled directly by the runtime, while composite types such as arrays, lists, or objects may involve references and mutation semantics. Understanding whether an assignment copies a value or a reference can often clarify unexpected behavior when working across languages.
Operators and expressions provide the mechanisms for computing and combining values. Arithmetic, comparison, and logical operators are broadly similar, but precedence rules and short-circuit evaluation can vary. Some languages provide operator overloading or additional operators for sequence manipulation and membership tests. When translating algorithms between languages, it is useful to verify how equality and identity are defined to avoid subtle bugs in comparisons or collection membership checks.
Control flow constructs determine the order of execution. Conditional statements, loop constructs, and exception or error handling form a shared vocabulary that can be mapped across syntaxes. For example, a conditional branch and a switch-like construct are present in many languages, though their exact forms and pattern-matching capabilities differ. Looping often appears as for, while, or iterator-based constructs; many modern languages also provide higher-order iteration tools that abstract explicit loop management.
Functions, modularity, and scope describe how code is organized and how names are resolved. Functions may be first-class values, allowing them to be passed and returned, or they may be more constrained. Scope rules — block scope, function scope, or lexical closures — influence name visibility and lifetime. Debugging approaches such as using interactive REPLs, logging, and step-through debuggers are common across ecosystems and can be selected based on the runtime and tooling available for a language.
Problem-solving patterns such as decomposition, iterative refinement, and basic data-structure selection are portable across syntaxes. Simple algorithms like searching, sorting, and traversal are typically expressed using the same conceptual steps even when implementation details differ. Recognizing these transferable patterns helps learners adapt to new environments by focusing first on algorithmic logic and second on language-specific syntax or libraries.
In summary, the subject centers on transferable programming ideas: storage and types, expression and operators, control flow, and modular organization. These concepts are implemented in different ways across languages such as Python, JavaScript, and Java, and awareness of their commonalities can reduce friction when learning additional languages. The next sections examine practical components and considerations in more detail.
Variables and naming conventions form the first layer of fundamental constructs. Most languages allow a programmer to name a storage location and associate it with a value; the scope and lifetime of that name depend on the language’s rules. For example, some languages use explicit declarations with types while others infer types at runtime. Understanding whether a variable name binds to an immutable value or a mutable reference can influence approach to state management and concurrency. Reading official language documentation often clarifies these binding semantics and avoids assumptions based on prior experience.
Data representation choices are an important practical consideration. Numerical types, boolean types, text strings, and collections appear in most languages but may carry different limits or default encodings. For instance, string immutability is common but not universal; collection mutability and iterator behaviors can affect performance and safety. When moving code between languages, verifying how a language implements common data structures (arrays, lists, maps) can prevent performance regressions or unexpected side effects.
Type systems influence how errors are detected and expressed. Statically typed languages typically report type mismatches at compile time, which may catch certain classes of errors earlier; dynamically typed languages may permit more rapid prototyping but can require additional runtime checks or tests. Hybrid systems that support gradual typing or optional annotations can offer a middle path. Each approach has trade-offs and the selection often depends on project scale, tooling, and team practices rather than an absolute technical superiority.
Memory and resource considerations are practical aspects of fundamental constructs. Some runtimes include automatic memory management and garbage collection, while others require explicit resource release patterns. Understanding how objects are allocated, when destructors or finalizers run (if at all), and how to manage I/O resources is often essential for robust code. These considerations may shape design decisions such as choosing immutable structures for concurrency or employing pooling strategies for frequently created objects.
Common data type categories include numeric types, booleans, text, and structured types like arrays and objects. Numeric types often include integers and floating-point numbers with platform-dependent ranges that may influence calculations involving large values. Text handling typically requires awareness of encoding; many modern languages use Unicode by default but behavior around normalization and byte-level operations can differ. For structured types, the distinction between value semantics and reference semantics can affect copying and mutation patterns.
Operator semantics can vary in subtle ways across languages. Equality operators may compare value equivalence or identity differently; some languages provide separate operators for strict versus loose equality. Operator precedence and associativity rules determine how expressions are evaluated and can cause surprises when porting code. Bitwise and logical operators are available in most languages, but their use may be more idiomatic in systems programming versus application-level code.
Type conversion and coercion are practical issues when combining different data types. Implicit conversions can simplify code but also introduce ambiguity, particularly in dynamically typed environments. Explicit conversion functions or casting mechanisms are commonly available and often preferable when porting algorithms between languages, since they make intent clearer and reduce runtime surprises. When performance is a concern, understanding the cost of conversions and boxing/unboxing operations may be relevant.
Collections and iteration idioms are tightly linked to data types and operators. Languages may provide index-based arrays, linked lists, or higher-level sequence abstractions with associated operators for mapping, filtering, and reducing data. Familiarity with these idioms can lead to clearer code and sometimes more efficient implementations. When learning a new language, reviewing its standard library for collection utilities typically yields patterns that replace manual loops with concise, higher-level expressions.
Control flow constructs like conditionals and selection statements allow a program to choose among alternative paths. If-then-else structures, switch or pattern-matching constructs, and conditional expressions are common across languages but differ in expressiveness and syntax. Pattern matching, where available, can simplify complex branching by matching structure rather than individual boolean conditions. When designing logic, expressing conditions clearly and avoiding deeply nested branches often leads to more maintainable code.
Repetition and iteration appear as explicit loops or implicit iteration constructs. For-loops, while-loops, and do-while-loops are widespread, while many modern languages also offer iterator patterns and higher-order functions for iteration. Using iterator protocols or generator constructs can reduce stateful loop management and may improve readability. When performance matters, selecting the appropriate iteration form — for example, index-based loops versus iterator-based loops — can have measurable effects depending on the runtime.
Error handling and exceptional control flow differ substantially across ecosystems. Some languages use exception-throwing mechanisms with try/catch blocks, while others favor result types or explicit error returns that must be checked. Each approach influences how callers must handle failure modes and can shape API design. Considering clarity of error propagation and avoiding broad catch-all handlers are practical considerations that may reduce silent failures and aid debugging.
Concurrency and asynchronous control flow are additional patterns relevant to repetition and sequencing. Event loops, threads, coroutines, and promises/futures represent various models for concurrent execution; each carries trade-offs in complexity and resource usage. Many common tasks are structured with asynchronous callbacks or await-style syntax that can simplify non-blocking operations. Understanding the concurrency model of a language helps avoid race conditions and guides suitable synchronization or immutability choices.
Functions encapsulate behavior and typically accept inputs and return outputs; they are a primary unit of abstraction. Different languages support varying function features such as default parameters, named arguments, variadic parameters, and anonymous functions (lambdas). Understanding parameter-passing semantics — by value, by reference, or by sharing a reference — helps predict how changes inside a function affect callers. Breaking problems into small, testable functions can improve clarity and facilitate unit testing.
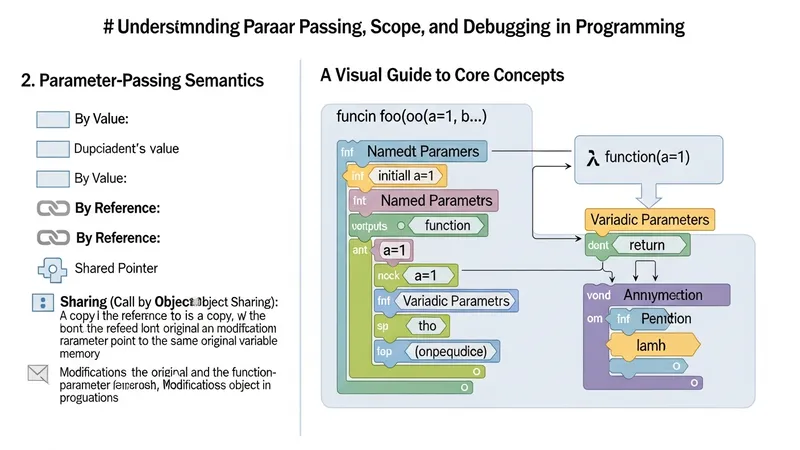
Scope rules determine where names are visible and how they are resolved. Lexical (static) scope, where a function’s environment is determined by its textual context, is common and supports closures when functions capture variables from enclosing scopes. Dynamic scope is less common but appears in some older or specialized languages. Awareness of shadowing, global state, and closure lifetimes is important to avoid unintentional interactions between modules and to reason about memory retention.
Debugging strategies include using interactive shells, logging, and step-through debuggers. Many language ecosystems provide REPLs that allow executing small code snippets and inspecting runtime state, which can accelerate experimentation. Structured logging with context and consistent error messages helps reproduce and analyze issues. Writing small, focused tests around functions can also surface regressions quickly and serve as an executable form of documentation for expected behavior.
Testing and basic verification complement debugging in producing reliable code. Unit tests, integration tests, and simple invariants asserted during development may reveal edge cases and guide refactoring safely. When porting logic between languages introduced earlier on the list — such as Python, JavaScript, and Java — translating tests alongside implementation can help confirm behavioral equivalence. These practices are considerations rather than prescriptions and may be adapted to the tooling available in each language’s ecosystem.